The Regex warrior: transform a text file in <2 mins
Daniel Leary5 min read

Recently I needed to transform a csv file with some simple processing. If you want to transform a file line by line, replacing a few things, deleting a few others, regular expressions are your friend.
Sed is a unix command line utility for modifying files line by line with regular expressions. It’s simpler than awk, and works very similarly to the vim substitution you may be vaguely familiar with.
We’re going to take a csv file and do the following with regex + sed:
- Delete some rows that meet a condition
- Delete a column (alright, I admit excel’s not bad for this one)
- Modify some cells in the table
- Move some data to its own column
We’ll be using this mock csv file data set:
name;id;thumbnail;email;url;admin;enabled
Dan Smith;56543678;dan_profile.jpg;dan@test.com;http://site.com/user/dan;false;true
James Jones;56467654;james_profile.png;james@test.com;http://site.com/user/james;false;true
Clément Girard;56467632;clement_profile.png;clement@test.com;http://site.com/user/clement;false;false
Jack Mack;56485367;jack_profile.png;jack@test.com;http://site.com/user/jack;true;false
Chris Cross;98453;chris_profile.png;chrisk@test.com;http://site.com/user/chris;true;true
Removing some users
First let’s remove users who are not enabled (last column == false). Sed lets us delete any line that return a match for a regex.
The basic structure of a sed command is like this:
sed 's/{regex match}/{substitution}/' <input_file >output_file
There’s also a delete command, deleting any line that has a match:
sed '/{regex match}/d' <input_file >output_file
Let’s use it
sed '/false$/d' <test.csv >output.csv

That command deletes these line in the csv:
Clément Girard;56467632;clement_profile.png;clement@test.com;http://site.com/user/clement;false;false
Jack Mack;56485367;jack_profile.png;jack@test.com;http://site.com/user/jack;true;false
Some of our users also have an old user Id (only 5 digits). Let’s delete those users from our csv too.
sed -r '/;[1-9]{5};/d' <test.csv >output.csv
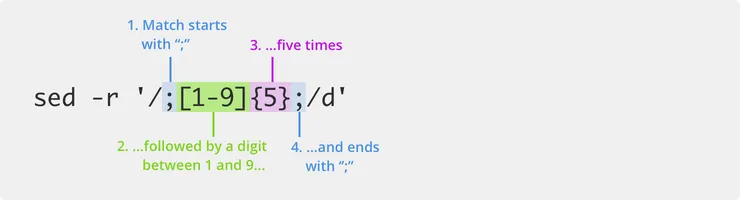
That command deletes this line in the csv:
Chris Cross;98453;chris_profile.png;chrisk@test.com;http://site.com/user/chris;true;true
Here we’re using the OR syntax: []. This means that the next character in the match will be one of the chars between the braces, in this case it’s a range of possible digits between 1 and 9.
We’re also using the quantifier {}, it repeats the previous character match rule 5 times, so will match a 5 digit number.
Note we added the -r flag to sed so that we could use regex quantifier. This flag enabled extended regular expressions, giving us extra syntax.
Removing a column
Next we want to remove the admin column. Removing the ‘admin’ column title is easy enough, but let’s use regex to remove the data. Our csv has 2 boolean columns, admin and enabled, we want to match both of these, and replace the match with just the ‘enabled column’, which we want to keep.
sed -r 's/(true|false);(true|false)$/\2/' <test.csv >output.csv

In this example we’ve used capture groups. By surrounding a match in parentheses, we can save it to a variable - the first capture is saved to ‘\1’, the second to ‘\2’ etc.
In the substitution section of our sed string, we replaced the entire match with capture group ‘\2’. In other words we’ve replaced the final two columns in each row with just the final column, thus removing the second-to-last column from the csv.
We’ve also used the pipe ’|’ as an OR operator, to match ‘true’ or ‘false’.
We’re left with a csv that looks like this:
name;id;thumbnail;email;url;enabled
Dan Smith;56543678;dan_profile.jpg;dan@test.com;http://site.com/user/dan;true
James Jones;56467654;james_profile.png;james@test.com;http://site.com/user/james;true
Modifying cells in the table
Next we’re going to modify the url column to store the relative url rather than the absolute path. We can use a regex like this:
sed 's_http:\/\/site[.]com\/\(.*\)_\1_' <test.csv >output.csv
This is very difficult to read because we have to escape each forward slash in the url with a backslash. Fortunately, we can change the sed delimiter from a forward slash to an underscore. This means we don’t have to escape forward slashes in the regex part of our sed command:
sed -r 's_http://site[.]com/(.*)_\1_' <test.csv >output.csv
That’s much more readable!
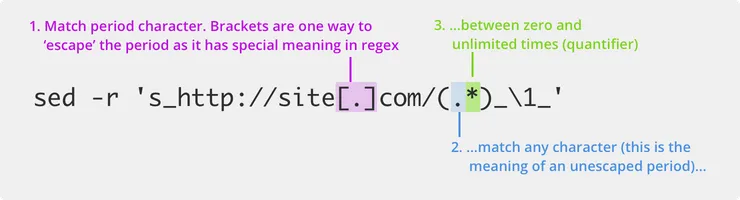
Here we match any characters after the base url using .* (this will match everything after the base url in the row). We save that in a capture group, so we now have a string starting with the relative url. By substituting the match with this, we’ve replaced the full url with the relative url.
We’re left with a csv that looks like this:
name;id;thumbnail;email;url;enabled
Dan Smith;56543678;dan_profile.jpg;dan@test.com;user/dan;true
James Jones;56467654;james_profile.png;james@test.com;user/james;true
Moving data to its own column
Finally, let’s take a column and split it into 2, moving some of its data to the new column. Let’s replace the name column with ‘first name’ and ‘last name’. We can start by renaming the headers in the first row, then use sed + regex to split each row in our csv in 2 automatically!
We could start with this:
sed -r 's/^([a-zA-Z]* )/\1;/' <test.csv >output.csv

Here we use OR square bracket [] notation again. In this case we match a character in a range of upper or lower case alphabetical characters. On Ubuntu Linux, this matches international alphabet characters like é, but this depends on your environment.
We save everything up to a space character (which delimits the first name from the last name) into a capture group and substitute it with itself plus a ’;’ - thus moving first name into its own column.
The problem with this is our first name is left with a trailing space character before the column delimiter (;). It would look like this:
first name;last name;id;thumbnail;email;url;enabled
Dan ;Smith;56543678;dan_profile.jpg;dan@test.com;user/dan;true
James ;Jones;56467654;james_profile.png;james@test.com;user/james;true
Instead, we can do something like this:
sed -r 's/^([a-zA-Z]*)( )(.*)$/\1;\3/' <test.csv >output.csv
This matches the space character, but also saves it into capture group ‘\2’. We then substitute the whole match with \1;\3 - effectively putting everything back together without the space, and putting a ’;’ character in its place. We now have our new columns, first name and last name.
There’s actually an even easier solution than this, we just replace the first empty space in each row with a ’;’ like this:
sed -r 's/ /;/' <test.csv >output.csv
That was fast and easy!
We’re left with a csv that looks like this:
first name;last name;id;thumbnail;email;url;enabled
Dan;Smith;56543678;dan_profile.jpg;dan@test.com;user/dan;true
James;Jones;56467654;james_profile.png;james@test.com;user/james;true
With only a few commands, we’ve managed to transform a csv from our terminal.


